
This blog series is a re-write of my original Gossip Sampling Library. A mountain of improvements have piled up and I thought it would be perfect to write about as I wrote the software. I hope you enjoy!
Introduction¶
A Gossip Protocol is a peer-to-peer communication method. It spreads information throughout a network in the same nature as gossip disseminates through a social circle. It is extremely flexible as it scales well and is fault tolerant. Because of this it has wide applications that fall into 3 major categories:
Dissemination Protocols¶
These are the rumor mongering protocols, ie. they are trying to broadcast information across the network.

Anti-Entropy Protocols¶
These are used to compare and alter data to maintain consistency and fix duplicated data.
Aggregation Protocols¶
The aggregation gossip protocol computes a network-wide aggregate through sampling information across every node and combining values.
One of my favorite applications of the gossip protocol is to train Machine Learning Models. I highly recommend you checkout Gossip Learning as a Decentralized Alternative to Federated Learning.
- data broadcasting
- robust fault-tolerance
- great scaling
- reduced bandwidth consumption
at the cost of:
- data consistency
- latency
Gossip Peer Sampling Service¶
So what is a Gossip Peer Sampling Service then? It maintains the gossip network and abstracts the details away from the user. Any program that wants to use this networking scheme simply asks the service for peers to talk to.
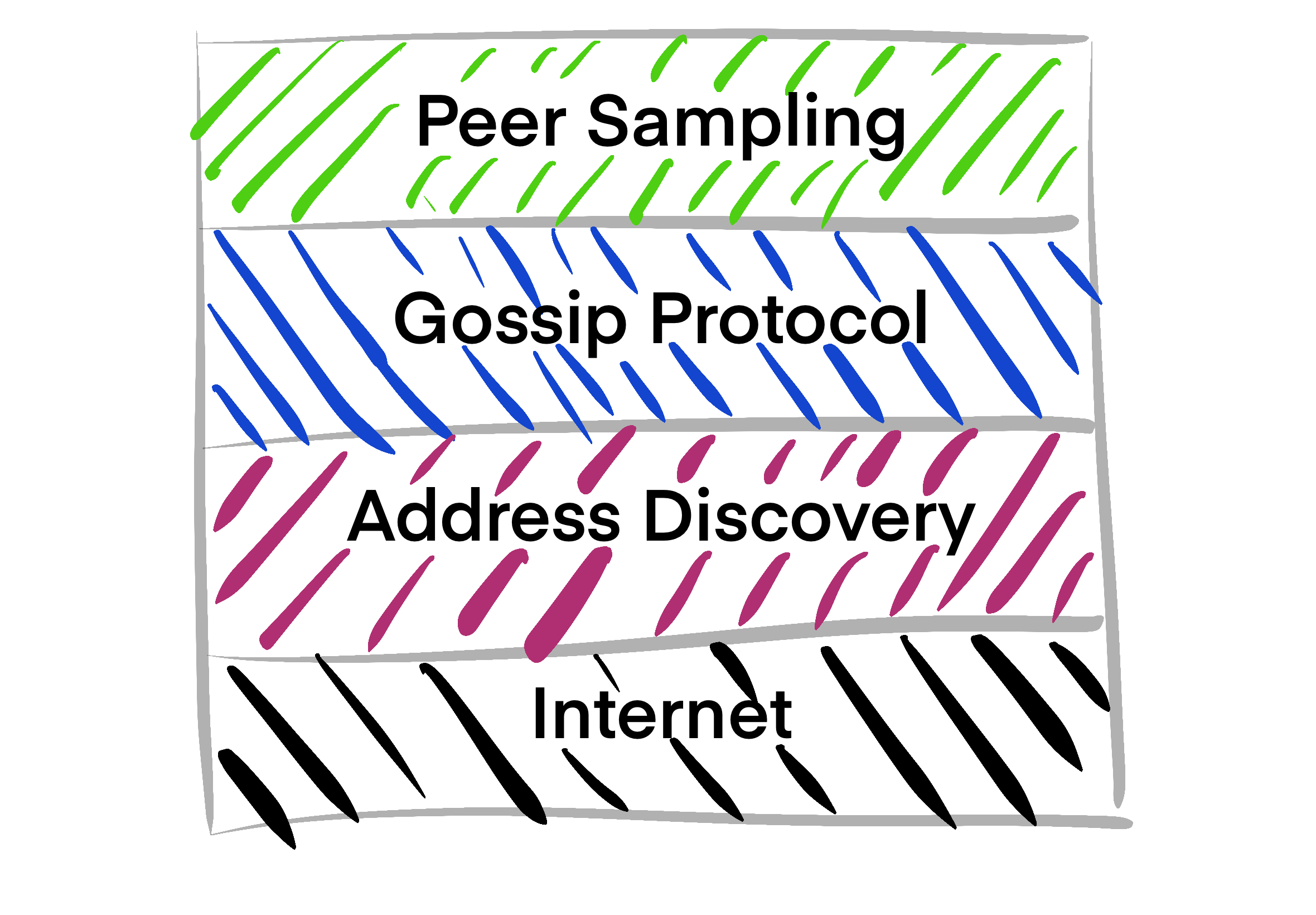
This is the first post of many in a series around creating a GPSS. I will post many tutorials and about design decisions and implementations as they come up. The idea is not to have a set in stone agenda, but more of an educational working log that shows the process.
My end goal is to have a library that is configurable and usable first and foremost for myself. I have several ideas I want to try out based around the Gossip Protocol but couldn’t find a good open source library for this sort of thing. If you follow along, you should be able to quickly get started using this for you’re own project.
The Theory¶
I highly recommend checking out both “Gossip-based Peer Sampling” and “The Promise, and Limitations, of Gossip Protocols” for an in-depth understanding. With that said I’ll go over some basics here for a high level overview of the parameter space of a Gossip Protocol and Sampling Methods. Finally, another good blog post about this topic is here.

Gossip Protocol¶
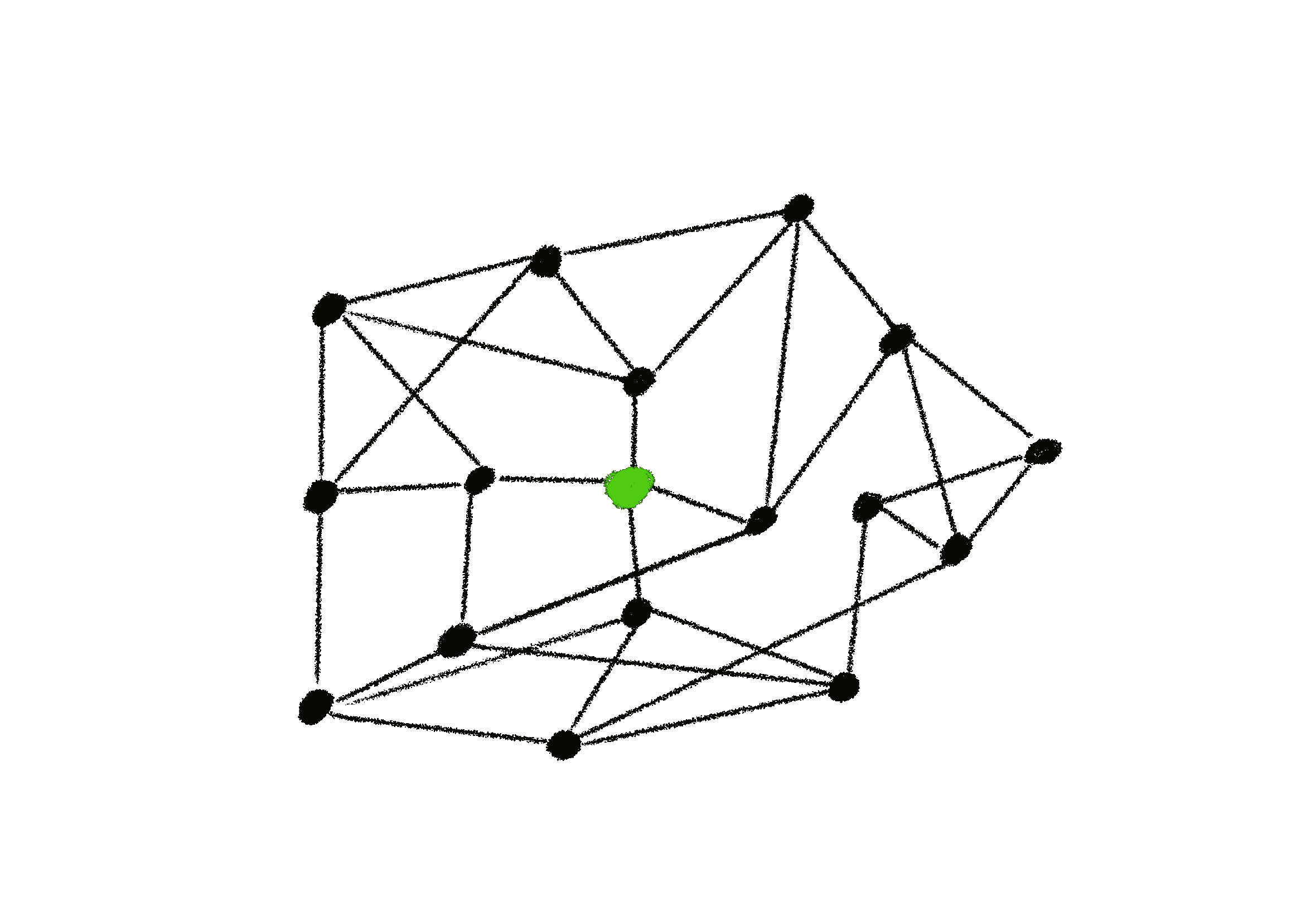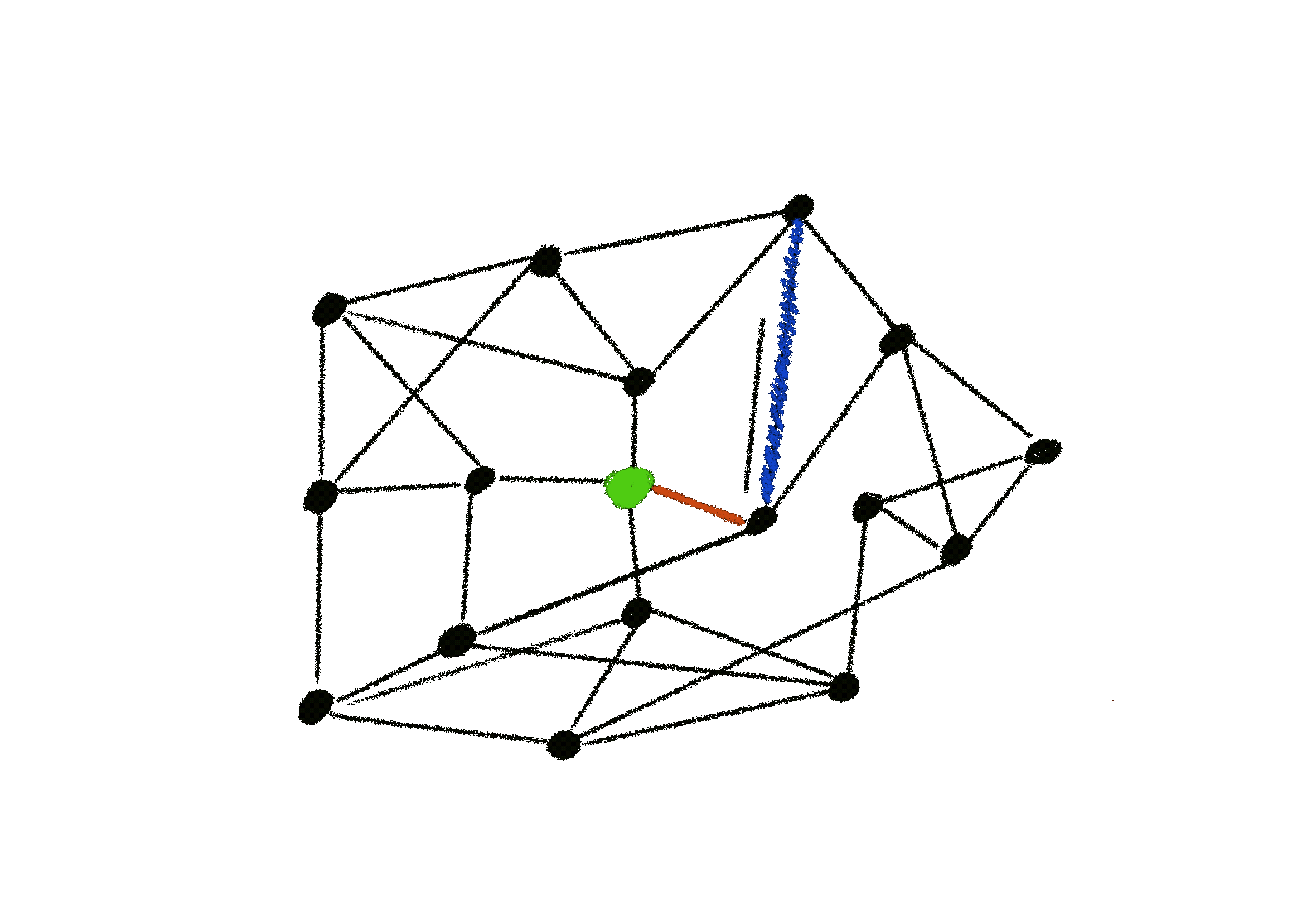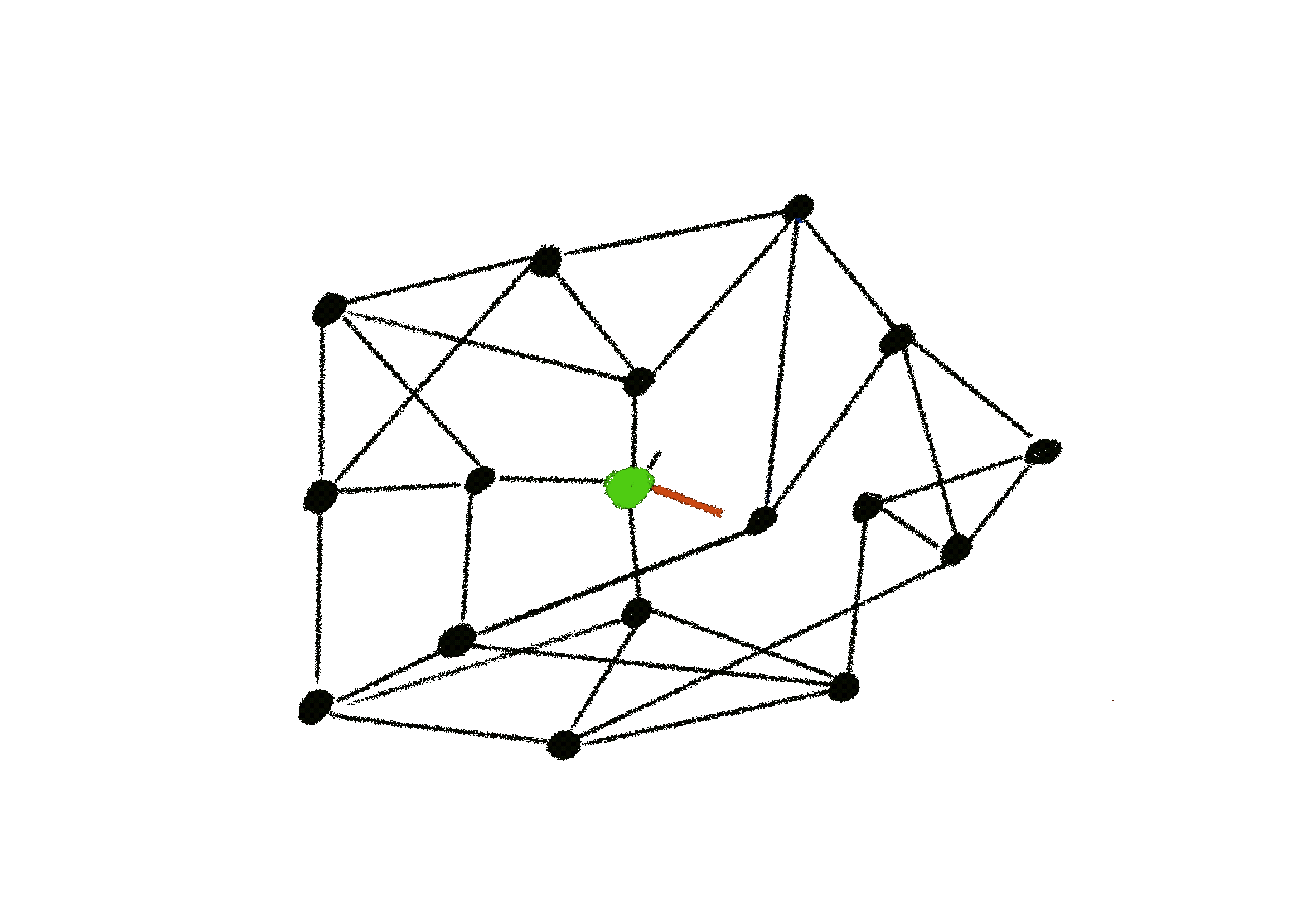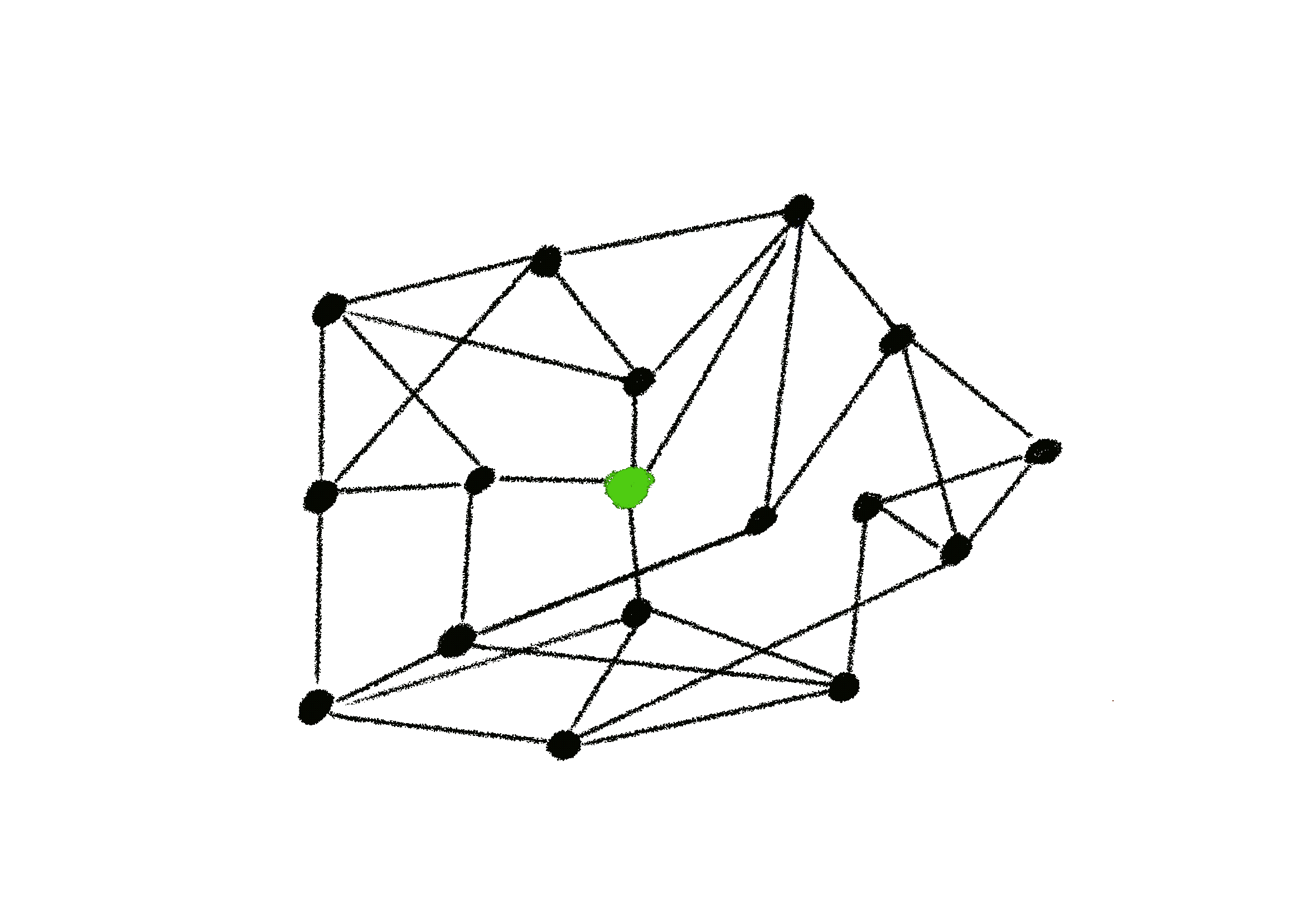
The basic idea of a gossip protocol, is that a node contains a view of the network. This view contains properties about other nodes in the network as well as how to address them. We manipulate this view by the following:
- Use some selection process to choose a peer[s] in our view
- Exchange nodes with the selected peer in a push, pull, or pushpull fashion
- Use some form of update method to incorporate the new nodes into and remove undesirable nodes from our view
Through this procedure, our current view of the network remains fresh and prunes undesirable connections.
Push¶
In a push only scenario, a node only ever sends their data to others
- Only efficient when a there a small amount of messages being passed and there is low churn.
- Can lead to poor load distribution in scenarios where the network grows or has high churn over time.
Pull¶
In pull only scenario, a node only ever requests data from others
- This is efficient when there are many update messages because it is highly likely to find a node with the latest update message.
- Pull only protocols never insert there own information into the network and thus will only gain information through there own active thread.
PushPull¶
In the PushPull scenario, a node both sends and requests data from others
- PushPull protocols quickly distribute load through the network regardless of growth and churn
- PushPull protocols disseminate message quickly and reliably
- Increases bandwidth usage
Cycle Time¶
This is the time each node in the network takes before initiating a new gossip exchange. Lower cycle times lead to:
- faster information propagation
- more up-to-date network topology
- high bandwidth usage
Fanout¶
Fanout is the number of peers that we talk to at one time. Larger fanout leads to:
- Faster data propagation
- high bandwidth usage
Sampling Service¶
A sampling service is the logic behind selecting peers from a populated view that is being maintained by a Gossip Protocol. Aka, we have these peers, what do we do with them? There are many ways to possibly do this, especially if you take a domain specific approach. However, I will focus (at least at first) on the 3 presented in “Gossip-based Peer Sampling”.
Head¶
This selects the peer with the lowest age. This does not work as it leads to only talking to peers you recently talked to. Ie. little diversity.
Tail¶
This selects the peer with the highest age. This helps promote diverse information sharing as it promotes talking to nodes that we have most likely not talked to before.
Uniform Random Without Replacement¶
To ensure a more diverse range of peers, once a peer is selected it will not be selected again until all peers have been selected. At this point we default to a uniform random selection from the entire view.
Embrace chaos? You’re heuristics mean nothing!
Summary¶
A Gossip Peer Sampling Service provides applications with a way to utilize a Gossip Overlay network without having the overhead of maintaining said network. This is desirable in large dynamic systems that want to check, aggregate, and disseminate information throughout a large number of nodes.